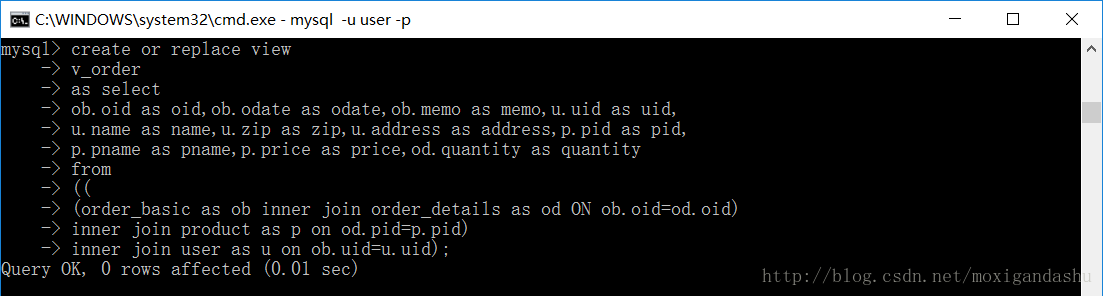
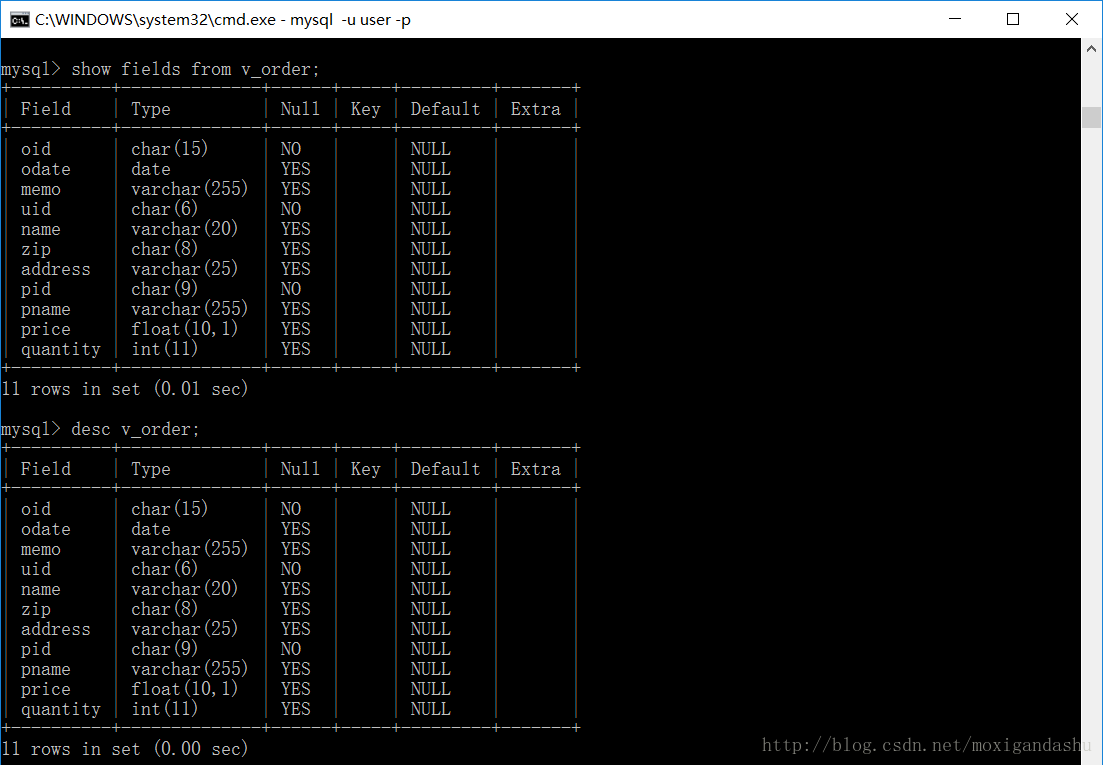
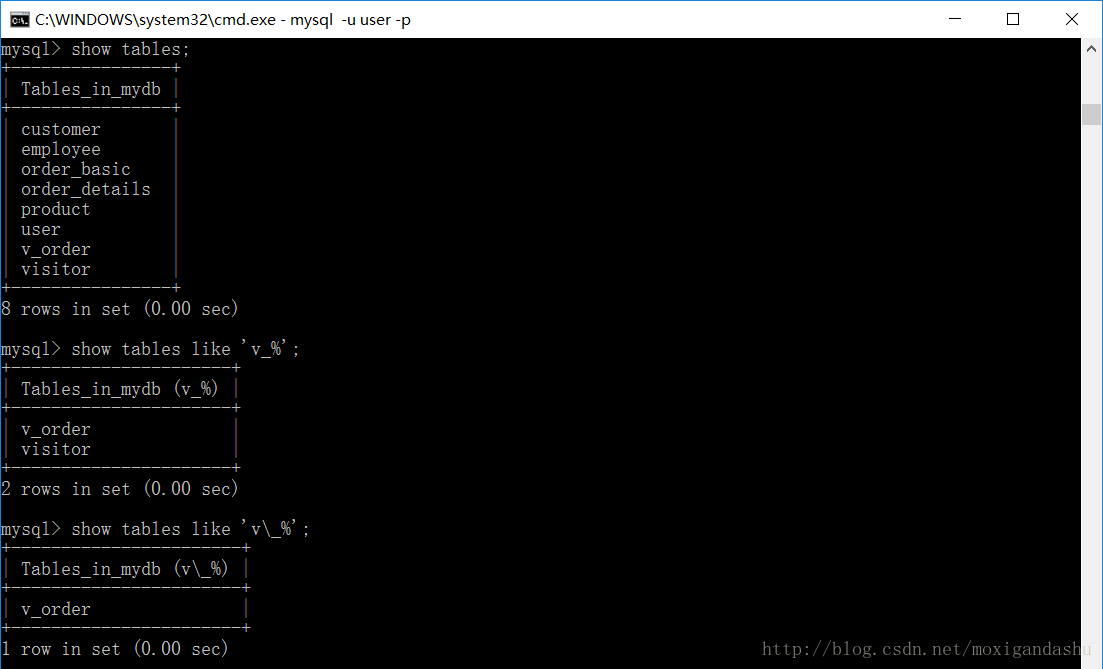
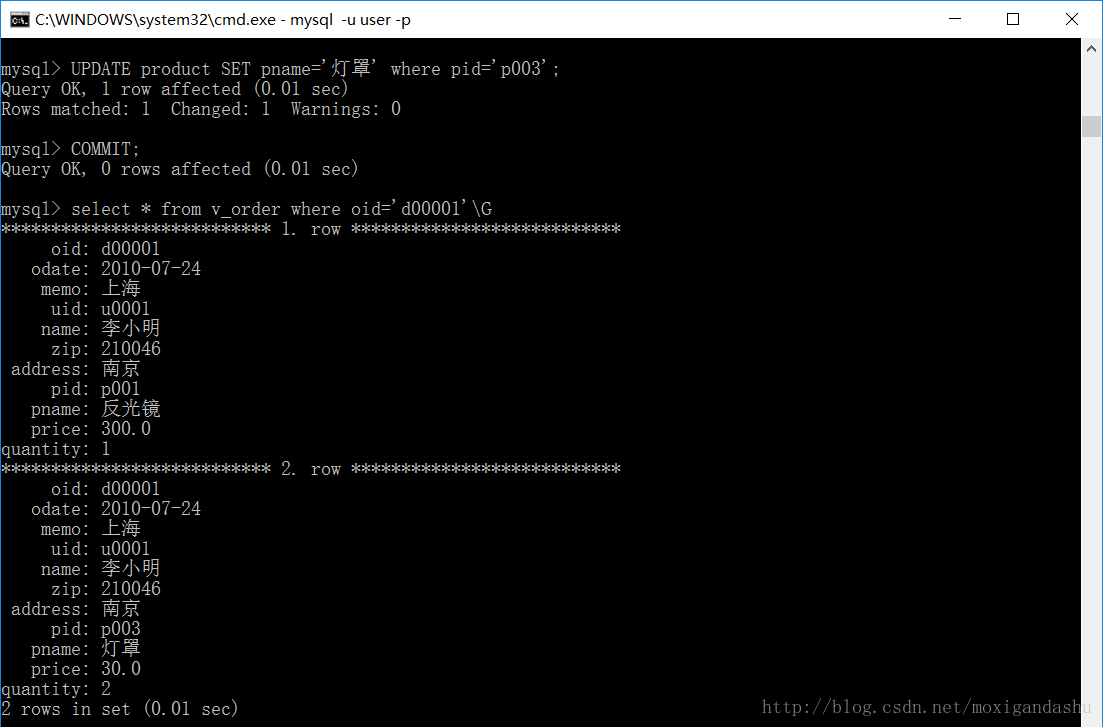
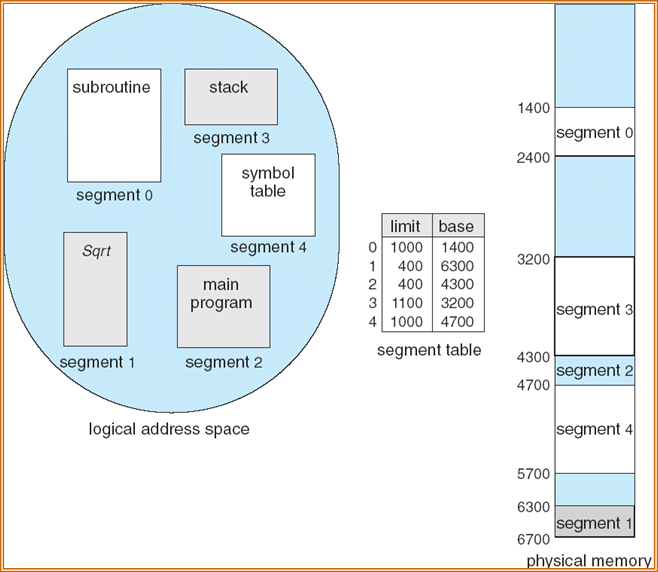
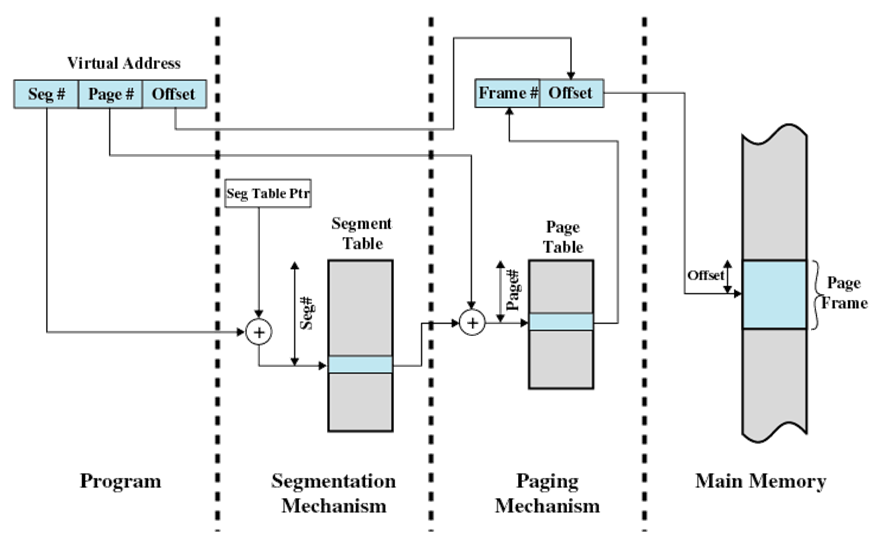
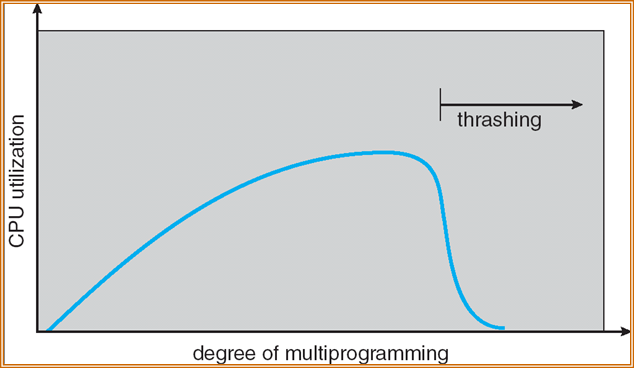
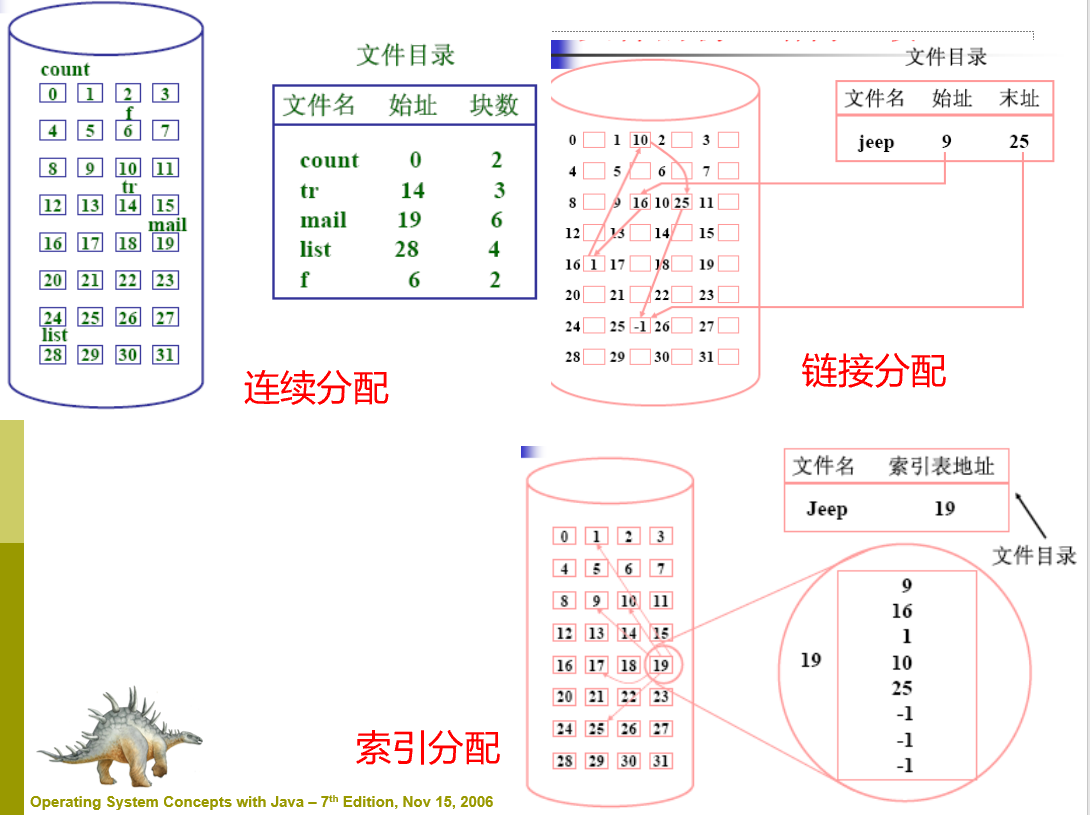
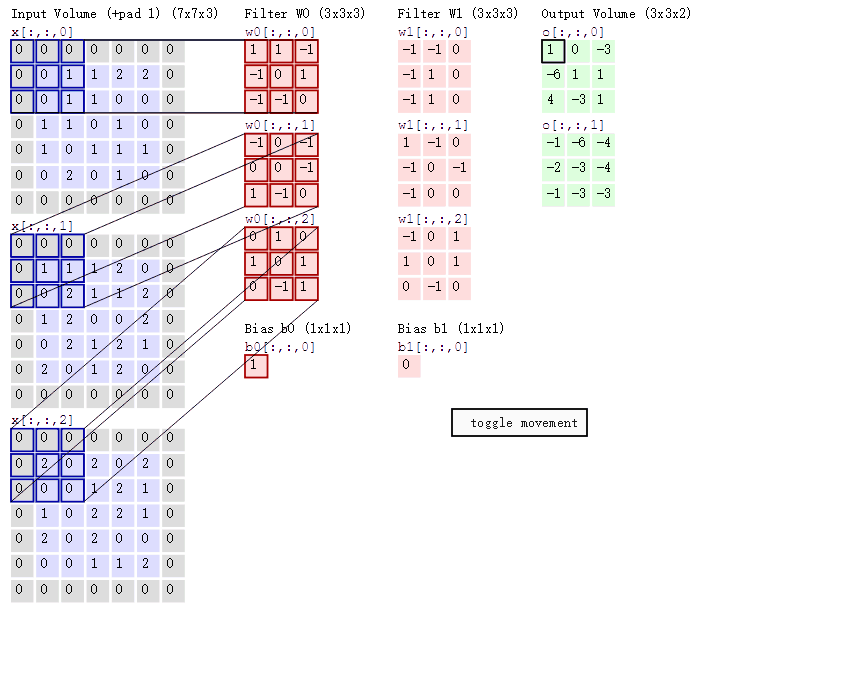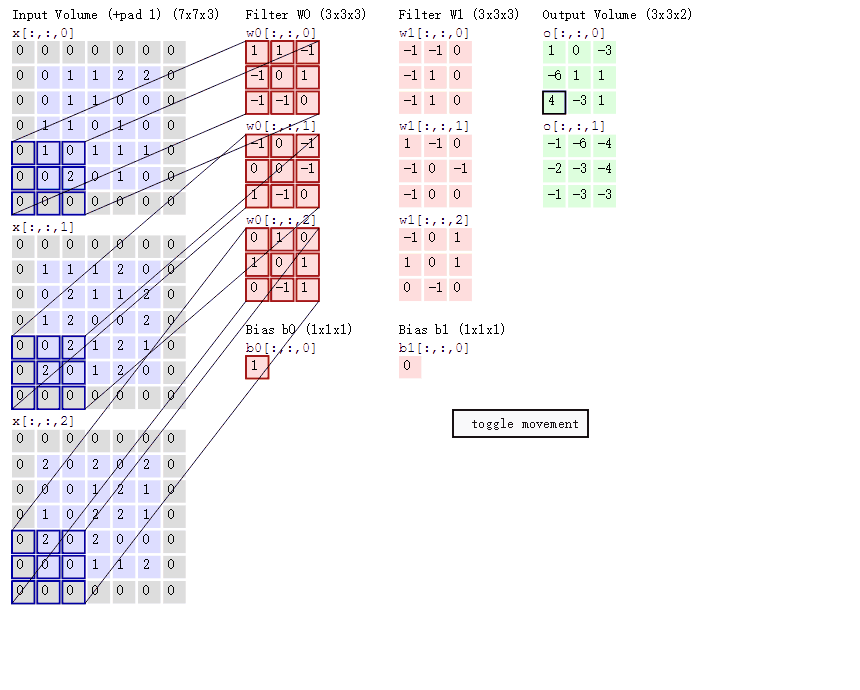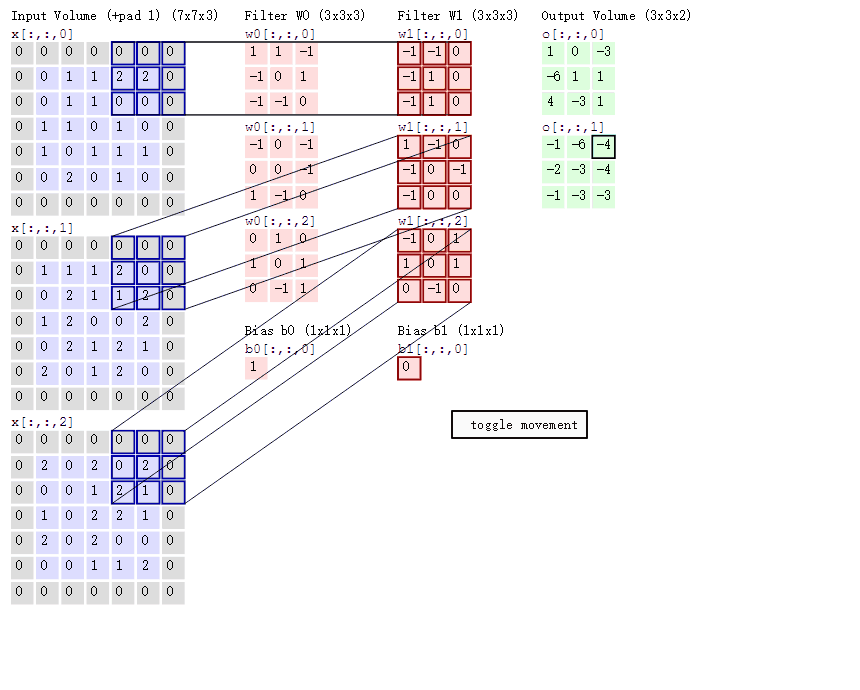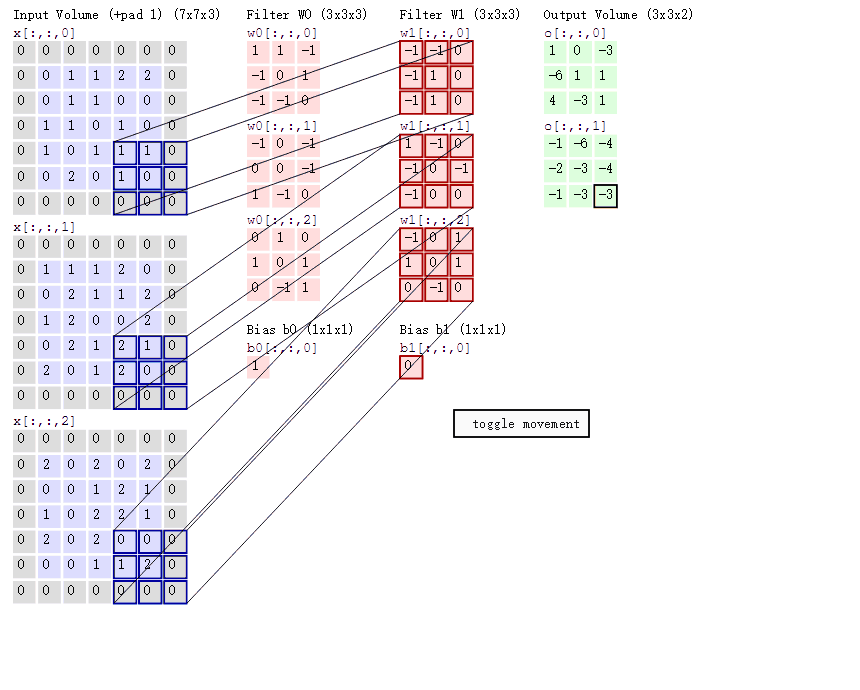
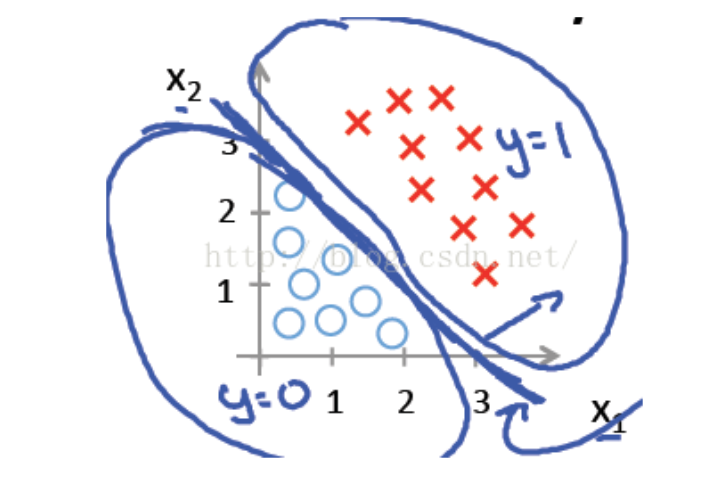
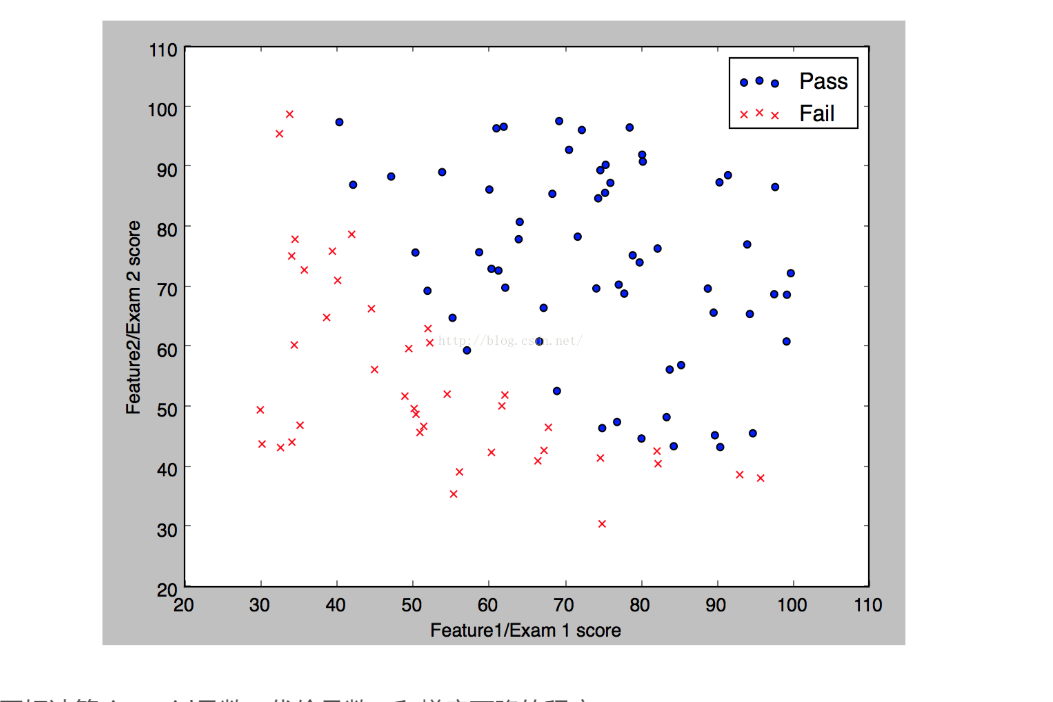
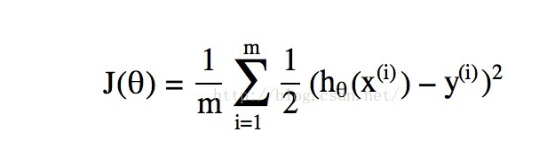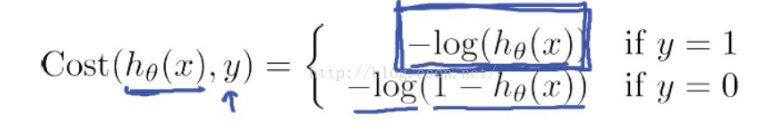首先是链表的结构定义:
1 | * Definition for singly-linked list. |
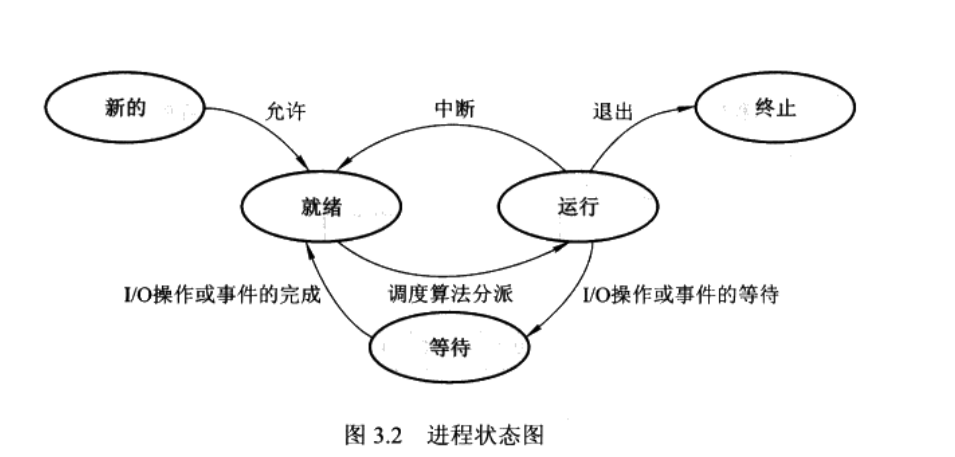
206.反转链表
给定一个链表头节点,将其反转,并输出新的头节点
1 | class Solution { |
时间复杂度为O(n), 空间复杂度O(1)
递归法:
1 | class Solution { |
92. 反转链表 II
反转从m到n的链表,请使用一趟扫描完成反转
说明:1$\le$m$\le$n$\le$链表长度
1 | 输入: 1->2->3->4->5->NULL, m = 2, n = 4 |
160. 相交链表
编写一个程序,找到连个单链表相交的起始节点。

解题思路:
从图中我们可以发现,在相交之后的链表长度是相同的,所以我们从头开始遍历知道两个链表长度相同时再逐个进行比较。
1 | class Solution { |
时间复杂度为O(n),空间复杂度为O(1)。
141. 环形链表
这类链表题目一般都是使用双指针法解决的,例如寻找距离尾部第K个节点、寻找环入口、寻找公共尾部入口等。
给定一个链表,判断链表中是否有环。
第一种结果: fast 指针走过链表末端,说明链表无环,直接返回 null;
TIPS: 若有环,两指针一定会相遇。因为每走 11 轮,fast 与 slow 的间距 +1+1,fast 终会追上 slow;

思路:使用快慢指针:快指针每次遍历两个节点,慢指针每次遍历一个节点,没有换很快回NULL,有的话两个指针将会相遇。
1 | class Solution { |
142. 环形链表 II
在141基础上进行改进,给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
方法1:使用SET或者哈希映射
对于每个节点,将其地址通过哈希映射或者直接存入到SET中,然后依次遍历链表,检测新节点是否已经在SET中或者已经被哈希映射。如果遍历结束,则说明没用环。如果遍历过程中发现该地址已经出现在哈希映射表或者SET中,则说明已经遍历过该节点,说明存在环,且该节点为入环节点。
1 | class Solution { |
上面的做法时间和空间效率都不高。
方法2:快慢指针法:
具体解法:
1 | class Solution { |
86. 分隔链表
给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前。
你应当保留两个分区中每个节点的初始相对位置。
1 | 输入: head = 1->4->3->2->5->2, x = 3 |
分析:可以设置两个辅助头结点,一个用来存储小于x的节点的链接,一个用来存储大于等于x的节点的链接。因此在此基础上遍历该链表,如果当前节点的之小于x,则将其加入到小于x的链表列,否则加入到大于等于x的链表列。最终,将两个链表合并即可。
1 | class Solution { |
83. 删除排序链表中的重复元素
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
1 | 输入: 1->1->2 |
1 | class Solution { |
82. 删除排序链表中的重复元素 II(递归)
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。在原来的基础上,只要重复出现了的元素全部删除。
头节点有重复的话将会比较麻烦,这里采用递归的思想:
每次对第一个节点进行检测,如果非重复,则将其加入,对后面继续执行。如果重复,则向后遍历直至与其不一致,执行遍历。
1 |
|
19. 删除链表的倒数第N个节点
1 | 给定一个链表: 1->2->3->4->5, 和 n = 2. |
思路1:删除倒数第n个,即正数第L-n-1个,我们用一个哑节点作为辅助从而简化情况。
1 | class Solution { |
思路二:通过一次遍历完成
上述算法可以优化为只使用一次遍历。我们可以使用两个指针而不是一个指针。第一个指针从列表的开头向前移动 n+1 步,而第二个指针将从列表的开头出发。现在,这两个指针被 n 个结点分开。我们通过同时移动两个指针向前来保持这个恒定的间隔,直到第一个指针到达最后一个结点。此时第二个指针将指向从最后一个结点数起的第 nn 个结点。我们重新链接第二个指针所引用的结点的 next 指针指向该结点的下下个结点。
1 | class Solution { |
结果要好一点点。
138. 复制带随机指针的链表
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
要求返回这个链表的 深拷贝。
我们用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
2. 两数相加
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
1 | 输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) |
1 | class Solution { |
148. 排序链表
如题,将链表排序。
通过快慢指针找到中点,然后用归并排序。
1 | class Solution { |