这只是一个很简单的介绍,并没有涉及到很深的知识。
1.特征工程简介
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。
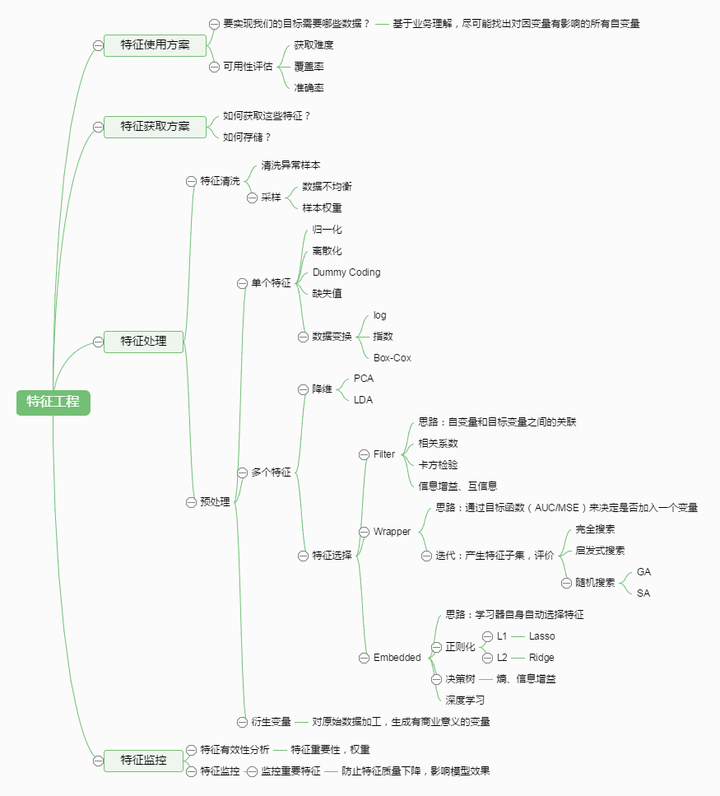
特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。
2.数据预处理
初始化的数据可能有各种各样的问题,所以我们要对数据进行数据预处理
- 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。
- 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。参考:通常使用哑编码的方式将定性特征转换为定量特征
- 存在缺失值
- 信息利用率低
2.0 数据清洗
1.基于统计的异常点检测算法
(1).简单统计分析:
比如对属性值进行一个描述性的统计,从而查看哪些值是不合理的,比如针对年龄来说,我们规定范围维 [0,100],则不在这个范围的样本,则就认为是异常样本
(2).3δ原则(δ为方差):
当数据服从正态分布:根据正态分布的定义可知,距离平均值3δ之外的概率为 P(|x-μ|>3δ) <= 0.003 ,这属于极小概率事件,在默认情况下我们可以认定,距离超过平均值3δ的样本是不存在的。 因此,当样本距离平均值大于3δ,则认定该样本为异常值
(3).通过极差和四分位数间距,进行异常数据的检测
2.基于距离的异常点检测算法(其实和K近邻算法的思想一样)
主要通过距离方法来检测异常点,将一个数据点与大多数点之间距离大于某个阈值的点视为异常点,主要使用的距离度量方法有绝对距离(曼哈顿距离)、欧氏距离和马氏距离等方法
3.基于密度的异常点检测算法
考察当前点周围密度,可以发现局部异常点
以上是临时补上去的
2.1无量纲化
顾名思义,我们处理数据要把他们转换成统一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
2.1.1标准化
很简单,一个函数的事
1 | StandardScaler().fit_transform() |
2.1.2 区间缩放法
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,应该很好理解。
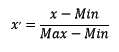
1 | MinMaxScaler().fit_transform(iris.data) |
2.1.3标准化和归一化的区别
标准化是依照特征矩阵的列处理数据,将样本的特征值转换到同一量纲下。
归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”,看下面的公式就行。
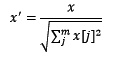
1 | Normalizer().fit_transform(iris.data) |
2.2 对定量特征二值化
很简单,设定一个阈值,然后:
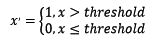
1 | Binarizer(threshold=3).fit_transform(iris.data) |
2.3 对定性特征哑编码
啥名词。。。
由于IRIS数据集的特征皆为定量特征,故使用其目标值进行哑编码(实际上是不需要的)。
1 | OneHotEncoder().fit_transform(iris.target.reshape((-1,1))) |
2.4 缺失值计算
终于来了个简单的了,这个看库就可以了,意思一下
1 | Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data))) |
2.5 数据变换
常见的数据变换有基于多项式的、基于指数函数的、基于对数函数的,下面是一个例子,说简单一点就是搞多一点数据。
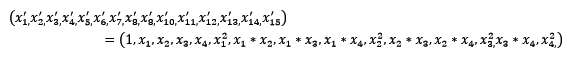
1 | PolynomialFeatures().fit_transform(iris.data) |
3.特征选择
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征,关键是选择特征啊:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
下面介绍三种特征选择方法:
3.1 Filter
3.1.1方差选择法
很好理解,使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
1 | VarianceThreshold(threshold=3).fit_transform(iris.data) |
3.1.2相关系数法:
这个不太懂
3.1.3卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。这个涉及到概率论的内容啊,忘得差不多了。
3.1.4 互信息法
信息论知识,经典的互信息也是评价定性自变量对定性因变量的相关性的,选取互信息最大的几个特征就行了
1 | \#选择K个最好的特征,返回特征选择后的数据 SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target) |
3.2 Wrapper
3.2.1 递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
3.3 Embedded
3.3.1 基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。直接上函数:
1 | SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target) |
这里等我以后遇到的时候再来写吧,有点麻烦
3.3.2 基于树模型的特征选择法
4.降维
当特征选择完成后,可以直接训练模型了,电脑太菜只能降维减少训练时间。
常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。
PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
这两种方法就两行代码,没什么参考意义
5.总结
这只是一个粗略的知识点介绍而已,在实际操作中是没有那么简单的,当然要达到你满意的结果需要很长时间的,这种事情以后慢慢说吧。话说还是掘金权威,知乎上的纯属科普。
参考来源:
作者:城东

