上次说了特征工程,这次照着别人的博客来复现一下kaggle上的hello world,python语法之类的我还是不熟悉,所以尽量把第一个项目做好,我这里仅仅是把大体的流程介绍一下,不会涉及到太多的语法。
作者: 寒小阳 出处:http://blog.csdn.net/han_xiaoyang/article/details/49797143
声明:版权所有,转载请注明出处,谢谢。
Github链接:https://github.com/HanXiaoyang/Kaggle_Titanic
题目链接:https://www.kaggle.com/c/titanic
背景
泰坦尼克号问题之背景
就是那个大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇的数量有限,无法人人都有,副船长发话了『lady and kid first!』,所以是否获救其实并非随机,而是基于一些背景有rank先后的。
训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。对,这是一个二分类问题,是我们之前讨论的logistic regression所能处理的范畴。
手把手教程马上就来,先来两条我看到的,觉得很重要的经验。
印象中Andrew Ng老师似乎在coursera上说过,应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高,所谓后续步骤可能包括『分析model现在的状态(欠/过拟合),分析我们使用的feature的作用大小,进行feature selection,以及我们模型下的bad case和产生的原因』等等。
Kaggle上的大神们,也分享过一些experience,说几条我记得的哈:
『对数据的认识太重要了!』
『数据中的特殊点/离群点的分析和处理太重要了!』
『特征工程(feature engineering)太重要了!在很多Kaggle的场景下,甚至比model本身还要重要』
『要做模型融合(model ensemble)啊啊啊!』
初探数据
1 | import pandas as pd #数据分析 |
得到典型的dataframe格式
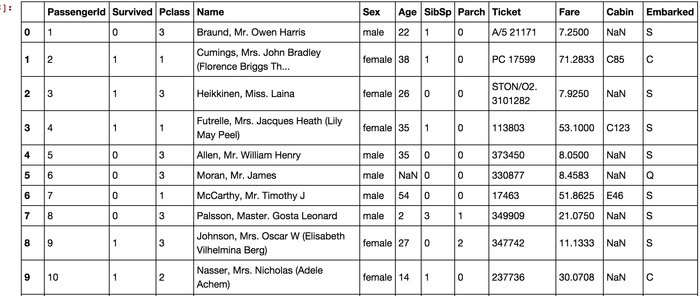
读取了数据之后,我们可以了解一下大体的情况
1 | #各个属性的数目以及百分比 |
数据初步分析
每个乘客都这么多属性,那我们咋知道哪些属性更有用,而又应该怎么用它们啊?说实话这会儿我也不知道,但我们记得前面提到过
- 『对数据的认识太重要了!』
- 『对数据的认识太重要了!』
- 『对数据的认识太重要了!』
重要的事情说三遍,恩,说完了。仅仅最上面的对数据了解,依旧无法给我们提供想法和思路。我们再深入一点来看看我们的数据,看看每个/多个 属性和最后的Survived之间有着什么样的关系呢。
接下来就是数据分析的内容了,我们分别考察下列情况:
乘客各属性分布(各个属性的人数)
然后是各个属性与获救结果的关联统计(看属性与获救结果是否有关)
ps:这个画图真有意思,这个库很不错
简单数据预处理
大体数据的情况看了一遍,对感兴趣的属性也有个大概的了解了。 下一步干啥?咱们该处理处理这些数据,为机器学习建模做点准备了。
对了,我这里说的数据预处理,其实就包括了很多Kaggler津津乐道的feature engineering过程,灰常灰常有必要!
- 『特征工程(feature engineering)太重要了!』
- 『特征工程(feature engineering)太重要了!』
- 『特征工程(feature engineering)太重要了!』
恩,重要的事情说三遍。
先从最突出的数据属性开始吧,对,Cabin和Age,有丢失数据实在是对下一步工作影响太大。
先说Cabin,暂时我们就按照刚才说的,按Cabin有无数据,将这个属性处理成Yes和No两种类型吧。
我们这里用scikit-learn中的RandomForest来拟合一下缺失的年龄数据(注:RandomForest是一个用在原始数据中做不同采样,建立多颗DecisionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法,我们之后会介绍到)
1 | from sklearn.ensemble import RandomForestRegressor |
然后我们就把数据补全了
因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。 什么叫做因子化呢?字面意思,把不是数值型的类目属性全都转成0,1的数值属性
1 | dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin') |
这样,看起来,是不是我们需要的属性值都有了,且它们都是数值型属性呢。
有一种临近结果的宠宠欲动感吧,莫急莫急,我们还得做一些处理,仔细看看Age和Fare两个属性,乘客的数值幅度变化,也忒大了吧!!如果大家了解逻辑回归与梯度下降的话,会知道,各属性值之间scale差距太大,将对收敛速度造成几万点伤害值!甚至不收敛! (╬▔皿▔)…所以我们先用scikit-learn里面的preprocessing模块对这俩货做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。
1 | import sklearn.preprocessing as preprocessing |
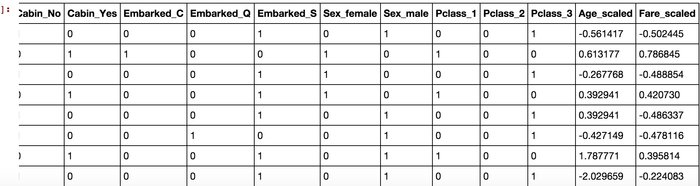
恩,好看多了,万事俱备,只欠建模。马上就要看到成效了,哈哈。
逻辑回归建模
我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模。
1 | from sklearn import linear_model |
good,很顺利,我们得到了一个model。
先淡定!淡定!你以为把test.csv直接丢进model里就能拿到结果啊…骚年,图样图森破啊!我们的”test_data”也要做和”train_data”一样的预处理啊!!
1 | data_test = pd.read_csv("/home/kesci/input/titanic8120/test.csv") |
然后就真的可以丢尽model了~
1 | test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*') |
结果符合预期,然后去make a submission啦啦啦!
逻辑回归系统优化
亲,你以为结果提交上了,就完事了? 我不会告诉你,这只是万里长征第一步啊(泪牛满面)!!!这才刚撸完baseline model啊!!!还得优化啊!!!
……未完持续,等我搞定baseline后再来继续优化
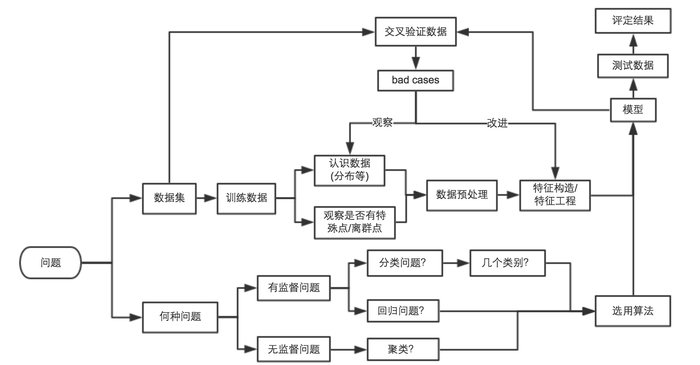
本文中用机器学习解决问题的过程大概如下图所示: