k-最近邻是基于实例的学习方法中最基本的算法。
基本描述
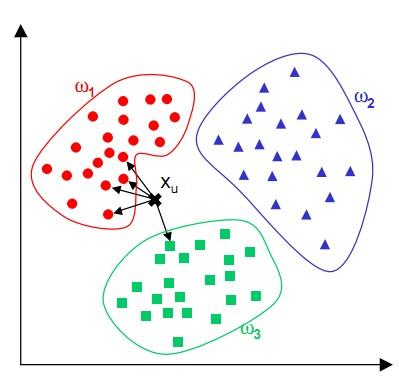
K最近邻(kNN,k-NearestNeighbor)分类算法,它的工作原理为:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。
在回归任务中可使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。既是最简单的机器学习算法之一,也是基于实例的学习方法中最基本的,又是最好的文本分类算法之一。
通过上面的描述,我们可以得知算法理论步骤:
1 | 1)算距离:给定测试对象,计算它与训练集中的每个对象的距离 |
算法优缺点
先来说说优点:
①简单,易于理解,易于实现,无需参数估计,无需训练;
②精度高,对异常值不敏感(个别噪音数据对结果的影响不是很大);
③适合对稀有事件进行分类;
④特别适合于多分类问题(multi-modal,对象具有多个类别标签),KNN要比SVM表现要好
再来说说缺点:
①KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多。
②类别评分不是规格化的(不像概率评分)。
③输出的可解释性不强,例如决策树的可解释性较强。 ④还有一点也很容易想到,就是如果我们样本很不平衡的时候,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。不过这个时候我们可以通过采取权值的方法改进(比如最近权值高)。
算法实现
算法应该很容易实现,下面来看看在kaggle中的手写数字识别中的实现:
首先我们完成将文件转化成向量的函数,方便读取:
1 | # convert image to vector |
然后我们加载整个数据库
1 | # load dataSet |
然后就是我们的knn算法了:
1 | # classify using kNN |
最后是测试函数:
1 | # test hand writing class |
由于这种题目的数据都是完整的,而且向量也是有规格的(32*32),也就是说每个测试例子都没有丢失的数据,而且每个参数的值也是在0-1的,所以这里不用进行数据处理阶段,至于要不要做特征工程我也不清楚。。。

