概念
逻辑回归是应用非常广泛的一个分类机器学习算法,它将数据拟合到一个logit函数(或者叫做logistic函数)中,从而能够完成对事件发生的概率进行预测。
由来
我们知道,线性回归可以预测出连续值结果,但是在生活中,我们是主要要解决分类问题,这个时候我们可以通过设定一个阈值来解决这个问题,但是这种模型很难对复杂的情况进行的分析。
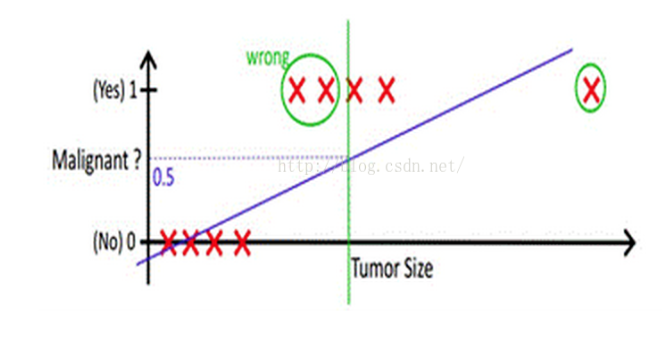
所以线性回归+阈值并不好,这个时候逻辑回归诞生了!
核心思想:线性回归的结果输出是一个连续值,而值的范围是无法限定的,那我们有没有办法把这个结果值映射为可以帮助我们判断的结果呢。ok,sigmoid函数可以实现这种功能。
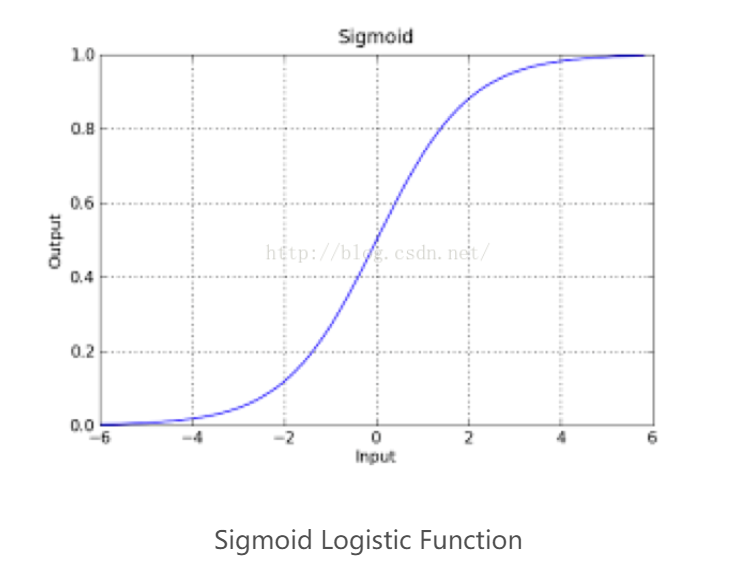
所以我们定义线性回归的预测函数为Y=WTX,那么逻辑回归的输出Y= g(WTX),其中y=g(z)函数正是上述sigmoid函数(或者简单叫做S形函数)。
判定边界
那么为什么通过把函数值限制在一定范围内就可以分类呢,我们还需要判定边界。可以理解为是用以对不同类别的数据分割的边界,边界的两旁应该是不同类别的数据。下面是一个例子:
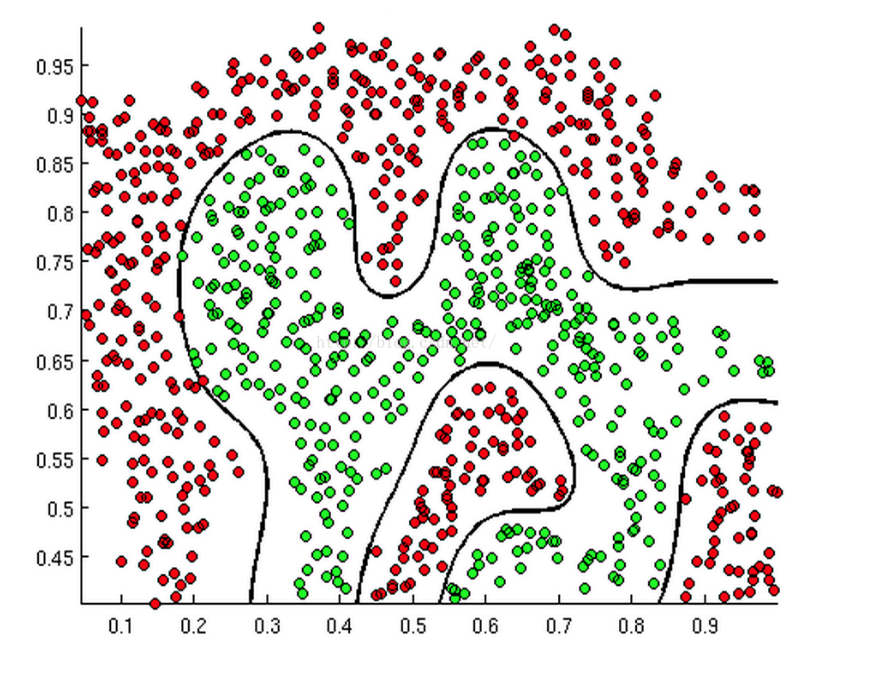
这个边界是没有规则的,那么逻辑回归是如何根据样本点获得这些边界的呢?
回到sigmoid函数,我们发现:
当g(z)≥0.5时,,z>=0,意味着y=1,故z=0是一个决策边界
解释:
hθ(x)的因变量取值区间是[0,1],并且关于坐标点(0,0.5)对称(可从Sigmoid Logistic Function图中看出来),所以以hθ(x)=g(θTX)=0.5的点为分界点,所以hθ(x)=g(θTX)≥0.5,时,则θTX≥0。而最后预估y的时候是把y分为两部分,分别用1和0去表示,hθ(x)=g(θTX)≥0.5的点表示为1,hθ(x)=g(θTX)≤0.5的点表示为0.
在逻辑回归中,z就是θTX。
先看第一个例子hθ(x)=g(θ0+θ1X1+θ2X2),其中θ0 ,θ1 ,θ2分别取-3, 1, 1。则当−3+X1+X2≥0时, y = 1; 则X1+X2=3是一个决策边界,图形表示如下,刚好把图上的两类点区分开来:
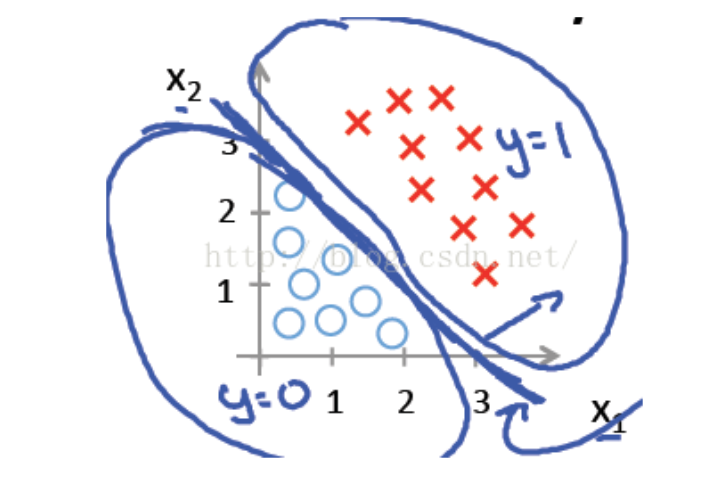
至于那些更复杂的曲线,hθ(x)也更复杂,这就是上面那个曲线边界出现的原因
代价函数与梯度下降
所以无论二维三维更高维,分类边界可以统一表示成h(x)=ΘTx,我们如何判定hθ(x)中的参数θ是否合适?如何选择θ?
我们要寻找出最佳参数Θ,使得对于1类别的点x,h(x)趋于正无穷,对于0类别的点x,h(x)趋于负无穷
跳过大量的证明,由cost函数的得知,我们是通过sigmoid函数进行的计算然后找出最佳的θ,从而得出合适的边界,在处理数据时我们通过边界判断。
(这个时候就不是判定边界的事情了,只要你的参数确定了,判定边界自然也就确定了,所以核心行还是参数的确定,这个时候需要用到数分的知识,通过多次迭代,找出代价最小的参数(可能有多个参数12345……),而我们是通过给定的代价函数求参数的)
所谓的代价函数Cost Function,其实是一种衡量我们在这组参数下预估的结果和实际结果差距的函数,下面是线性回归的代价函数,比较直观:
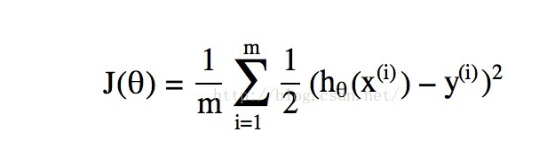
当然核心是选择合适的参数θ,我们要找到 有曲面为碗状的作为合适的代价函数g(θTx)好像并不符合这种特性,
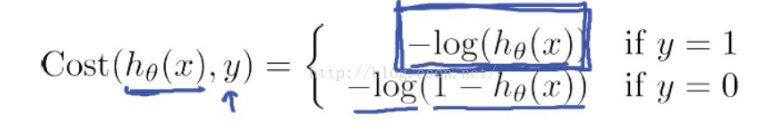
这个函数有很好的惩罚效果,具体推理会在西瓜上总结
下面我们说说梯度下降,梯度下降算法是调整参数θ使得代价函数J(θ)取得最小值的最基本方法之一。从直观上理解,就是我们在碗状结构的凸函数上取一个初始值,然后挪动这个值一步步靠近最低点的过程
从数学上理解,我们为了找到最小值点,就应该朝着下降速度最快的方向(导函数/偏导方向)迈进,每次迈进一小步,再看看此时的下降最快方向是哪,再朝着这个方向迈进,直至最低点。这个应该不难理解吧。
这个部分唯一的疑点就是我变量的幂要怎么选取(非线性的话要对变量进行映射)
代码与实现
只有实践能够解决所有疑问,上面说那么多没啥用的。
下面是python画出的一份数据图
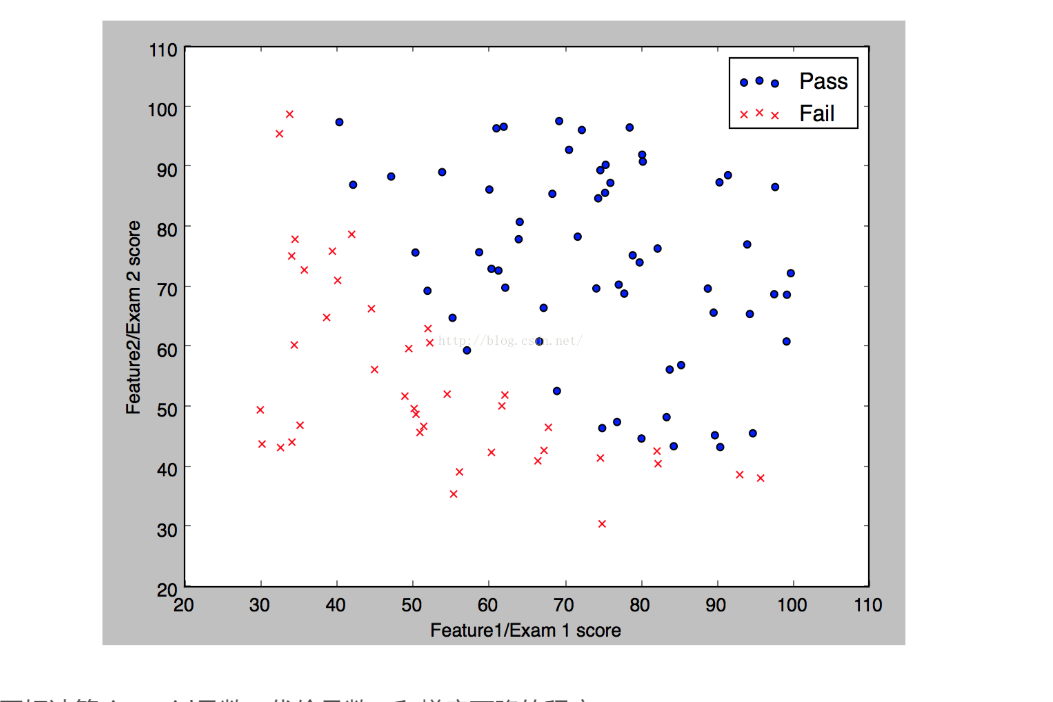
我们来看看关键的代码实现
1 | #sigmoid函数 |
总结
它始于输出结果为有实际意义的连续值的线性回归,但是线性回归对于分类的问题没有办法准确而又具备鲁棒性地分割,因此我们设计出了逻辑回归这样一个算法,它的输出结果表征了某个样本属于某类别的概率。
而直观地在二维空间理解逻辑回归,是sigmoid函数的特性,使得判定的阈值能够映射为平面的一条判定边界,当然随着特征的复杂化,判定边界可能是多种多样的样貌,但是它能够较好地把两类样本点分隔开,解决分类问题。
求解逻辑回归参数的传统方法是梯度下降,构造为凸函数的代价函数后,每次沿着偏导方向(下降速度最快方向)迈进一小部分,直至N次迭代后到达最低点。
总结一下思绪,logistic回归的任务就是要找到最佳的拟合参数,从而得出边界,从而可以对数据进行判断。。
不愧是逻辑回顾,先撤了,具体的实现过一阵子看看,现在会用逻辑回归就行了。
又回来看了一下,才发现sigmoid函数的精妙之处,希望有时间能将数学证明过一遍。
参考资料:http://blog.csdn.net/han_xiaoyang/article/details/49123419

